Deploy High Availability PostgreSQL Clusters on Kubernetes by Example
Crunchy Data
9 min readMore by this author
One of the great things about PostgreSQL is its reliability: it is very stable and typically “just works.” However, there are certain things that can happen in the environment that PostgreSQL is deployed in that can affect its uptime, such as:
- The database storage disk fails or some other hardware failure occurs
- The network on which the database resides becomes unreachable
- The host operating system becomes unstable and crashes
- A key database file becomes corrupted
- A data center is lost
There may also be downtime events that are due to the normal case of operations, such as performing a minor upgrade, security patching of operating system, hardware upgrade, or other maintenance.
Fortunately, the Crunchy PostgreSQL Operator is prepared for this.
Crunchy Data recently released version 4.2 of the open source PostgreSQL Operator for Kubernetes. Among the various enhancements included within this release is the introduction of distributed consensus based high availability (HA) for PostgreSQL clusters by using the Patroni high availability framework.
What does this mean for running high availability PostgreSQL clusters in Kubernetes, how does it work, and how to create a high availability PostgreSQL cluster by example? Read on to find out!
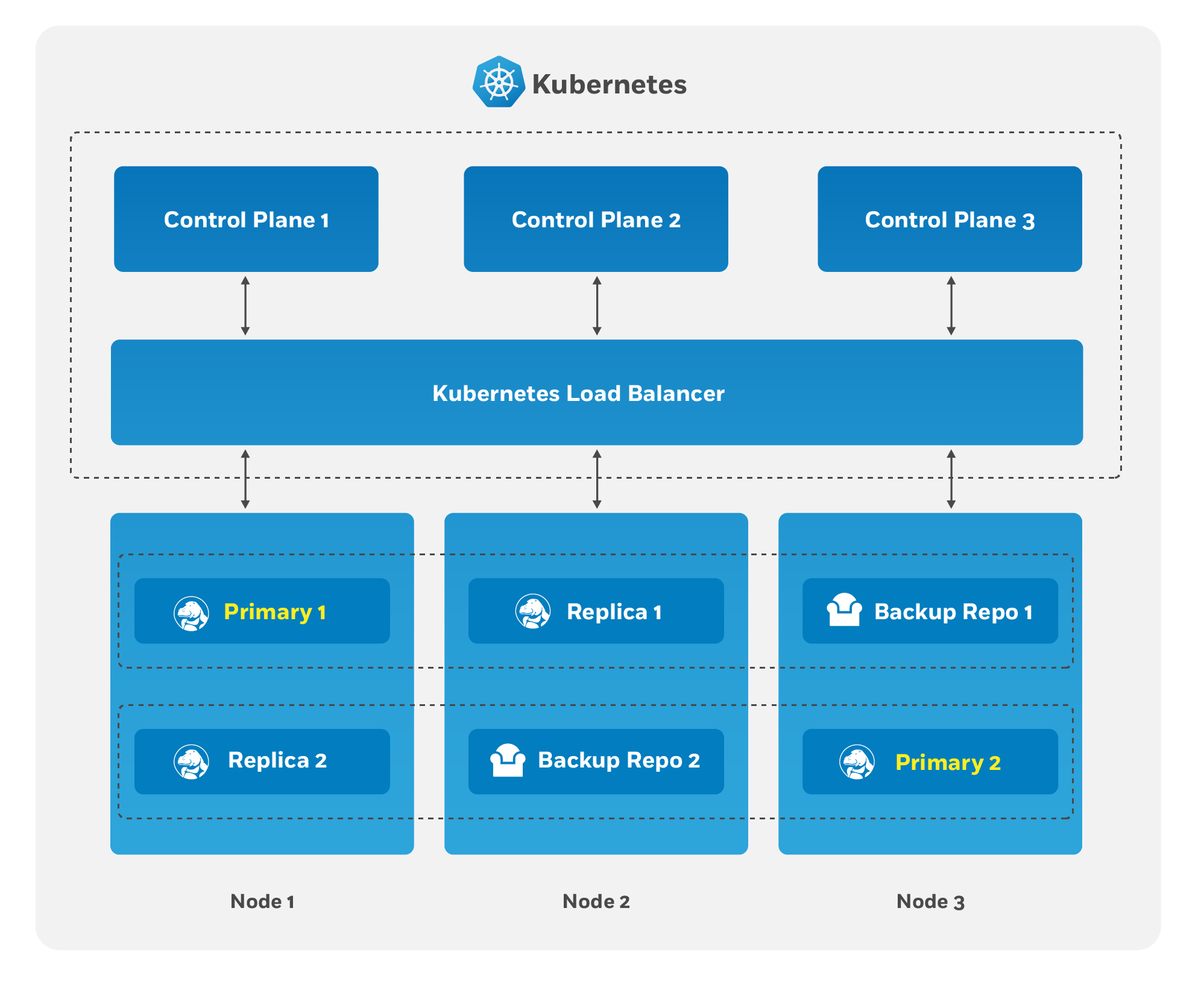
The Crunchy PostgreSQL Operator High Availability Fundamentals
To make the PostgreSQL clusters deployed by the PostgreSQL Operator resilient to the types of downtime events that affect availability, the Crunchy PostgreSQL Operator leverages the distributed consensus store (DCS) that backs Kubernetes to determine if the primary PostgreSQL database is in an unhealthy state. The PostgreSQL instances communicate amongst themselves via the Kubernetes DCS to determine which one is the current primary and if they need to failover to a new primary.
This is the key to how the PostgreSQL Operator provides high availability: it delegates the management of HA to the PostgreSQL clusters themselves! This ensures that the PostgreSQL Operator is not a single-point of failure for the availability of any of the PostgreSQL clusters that it manages, as the PostgreSQL Operator is only maintaining the definitions of what should be in the cluster (e.g. how many instances in the cluster, etc.). This is similar to what you find in the outline of the Raft algorithm that describes how to provide consensus amongst who is the leader (or primary) instance in a cluster.
(A quick aside: the Raft algorithm (“Reliable, Replicated, Redundant, Fault-Tolerant”) was developed for systems that have one “leader” (i.e. a primary) and one-to-many followers (i.e. replicas) to provide the same fault tolerance and safety as the PAXOS algorithm while being easier to implement. Given PostgreSQL runs as one primary and however many replicas you want, it is certainly appropriate to use Raft. PostgreSQL clusters managed by the PostgreSQL Operator, via Patroni, leverage Raft properties of the Kubernetes DCS so that way you can run a smaller number of PostgreSQL instances (i.e. 2) and still have distributed consensus!)
For the PostgreSQL cluster group to achieve distributed consensus on who the primary (or leader) is, each PostgreSQL cluster leverages the distributed etcd key-value store that is bundled with Kubernetes. After the PostgreSQL clusters elect a leader, a primary will place a lock in the distributed cluster to indicate that it is the leader. The "lock" is how the primary PostgreSQL instance will provide its heartbeat: it will attempt to periodically update the lock and so long as the other replicas see the update in the allowable automated failover time, the replicas will continue to follow the current primary.
The “log replication” portion that is defined in the Raft algorithm, the primary instance will replicate changes to each replica based on the rules set up in the provisioning process. Each replica keeps track of how far along in the recovery process it is using a “log sequence number” (LSN), a built-in PostgreSQL serial representation of how many logs have been replayed on each replica. For the purposes of high availability, there are two LSNs that need to be considered: the LSN for the last log received by the replica, and the LSN for the changes replayed for the replica. The LSN for the latest changes received can be compared amongst the replicas to determine which one has replayed the most changes, and an important part of the automated failover process.
For PostgreSQL clusters that leverage “synchronous replication,” a transaction is not considered complete until all changes from those transactions have been sent to all replicas that are subscribed to the primary.
Determining When to Failover, And How It Works
As mentioned above, the PostgreSQL replicas periodically check in on the lock to see if it has been updated by the primary within the allowable time. If a replica believes that the primary is unavailable, it becomes what is called a "candidate" according to the Raft algorithm and initiates an "election." It then votes for itself as the new primary. A candidate must receive a majority of votes in a cluster in order to be elected as the new primary. The replicas try to promote the PostgreSQL instance that is both available and has the highest LSN value on the latest timeline.
This system protects against a replica promoting itself when the primary is actually still available. If a replica believes that a primary is down and starts an election, but the primary is actually not down, the replica will not receive enough votes to become a new primary and will go back to following and replaying the changes from the primary.
Once an election is decided, the winning replica is immediately promoted to be a primary and takes a new lock in the Kubernetes consensus store. If the new primary has not finished replaying all of its transactions logs, it must do so in order to reach the desired state based on the LSN. Once the logs are finished being replayed, the primary is able to accept new queries.
At this point, any existing replicas are updated to follow the new primary.
Notice not once did I say anything about the PostgreSQL Operator here. This is the beauty of this high availability method: the PostgreSQL Operator allows for the administration of the PostgreSQL clusters and can set their overall structure (e.g. have 3 PostgreSQL instances in a cluster), but it does not manage their availability. This ensures that the PostgreSQL Operator is not a single-point-of-failure!
Automatic Healing of the Failed Primary
One of the most important pieces of this kind of failover is being able to bring back the old primary into the fold as one of the replicas. For very large databases, this can be a challenge if you have to reinitialize the database from scratch. Fortunately, the PostgreSQL Operator provides a way for the failed primary to automatically heal!
When the old primary tries to become available again, it realizes that it has been deposed as the leader and must be healed. It leverages the pgBackRest repository that is deployed alongside the PostgreSQL cluster and uses the “delta restore” feature, which does an in place update of all of the missing files from the current primary. This is much more efficient than reprovisioning the failed instance from scratch, and works well for very large databases! When the delta restore is done, the instance is considered heal and is ready to follow the new primary.
Less Talk, More Examples
Now that you understand how this all works let's look at an example!
For the 4.2 release, we tested a variety of scenarios that would trigger a failover, from network splits (my favorite one to test) to critical file removal to the primary pod disappearing. For the purposes of this exercise, we will try out the last case as it is a very easy experiment to run.
First, I have gone ahead and deployed the PostgreSQL Operator to a Kubernetes cluster. I have set up my cluster to use the PostgreSQL Operator client, aka pgo.
Let's create a high availability PostgreSQL cluster with two replicas using the pgo create cluster command:
pgo create cluster hippo --replica-count=2
Notice I don't add any extra flags: high availability is enabled by default in the PostgreSQL Operator starting with version 4.2. If you want to disable high availability, you must use the --disable-autofail flag.
(Also note that you may need to explicitly pass in the Kubernetes Namespace with the -n flag. I set the PGO_NAMESPACE environmental variable to automatically use the Namespace).
Give the cluster a few minutes to get started. At some point, all of your PostgreSQL instance should be available, which you can test with the pgo test command:
pgo test hippo
cluster : hippo
Services
primary (10.96.130.226:5432): UP
replica (10.96.142.11:5432): UP
Instances
primary (hippo-9d5fb67c9-6svhm): UP
replica (hippo-dupt-775c5fc66-fc7vh): UP
replica (hippo-sekv-5f88dcbc5b-748zl): UP
Under the instances section, you can see the name of the Kubernetes Pods that comprise the entirety of the PostgreSQL cluster. Take note of the name of the primary Pod for this cluster, which in this example is hippo-9d5fb67c9-6svhm. Let's have this Pod meet with an unfortunately accident (note, you may need to add a Namespace to this command with a -n flag).:
kubectl delete pods hippo-9d5fb67c9-6svhm
When demonstrating automatic failover with this method, you may notice that you kubectl command hangs for a few moments. This is due to Kubernetes making its updates after the failover event is detected.
Wait a few moments, and run pgo test again to see what happens:
pgo test hippo
cluster : hippo
Services
primary (10.96.130.226:5432): UP
replica (10.96.142.11:5432): UP
Instances
replica (hippo-9d5fb67c9-bkrht): UP
replica (hippo-dupt-775c5fc66-fc7vh): UP
primary (hippo-sekv-5f88dcbc5b-748zl): UP
Wow! Not only did a new primary PostgreSQL cluster get elected, but we were able to automatically heal the old primary and turn it into a replica. Granted, this may be far more impressive if we had some more data in the database and I demonstrated the continuity of the availability, but this is already a long article. ;-)
Conclusion & Further Reading
Using Kubernetes to run high availability PostgreSQL clusters is no easy task: while the fundamental building blocks are available to create this kind of environment, it does require some smarts and automation behind it. Fortunately, the PostgreSQL Operator
If you want to understand more how the PostgreSQL Operator creates high availability PostgreSQL environments, I encourage you to read the high availability architecture section in our documentation.
I also encourage you to deploy the PostgreSQL Operator and try creating your own downtime scenarios and see what happens. We'd love to iron out any edge cases that may occur (though some may be too out on the edge, and at that point you'd still need manual intervention. But hey, we'd like to try to automate it, and maybe you could propose a patch to automate it!), but most importantly, we'd love to understand how you deploy high availability PostgreSQL!
Related Articles
- Hybrid Search Patterns with Postgres and pgvector
13 min read
- Postgres 19 Compression: from pglz to LZ4
8 min read
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read