One of the things that makes Postgres so powerful for data integrity is the incredibly useful system of constraints. Constraints are a way to tell Postgres which kinds of data can be inserted into tables, columns, or rows. Adding logic into your database to protects your data from bad data, null statements or application code that isn't working quite right and does not conform to your data requirements. Constraints are also great for catching outliers and things you didn’t account for in application code, but you know need to be caught before an insert statement.
To illustrate the major constraint types, we are going to show you an example database schema where you’re building a room reservation system with a table for users, a table for rooms, and reservations tables referencing users and rooms along with a start and end time. This is the same schema as the Table Creation tutorial.
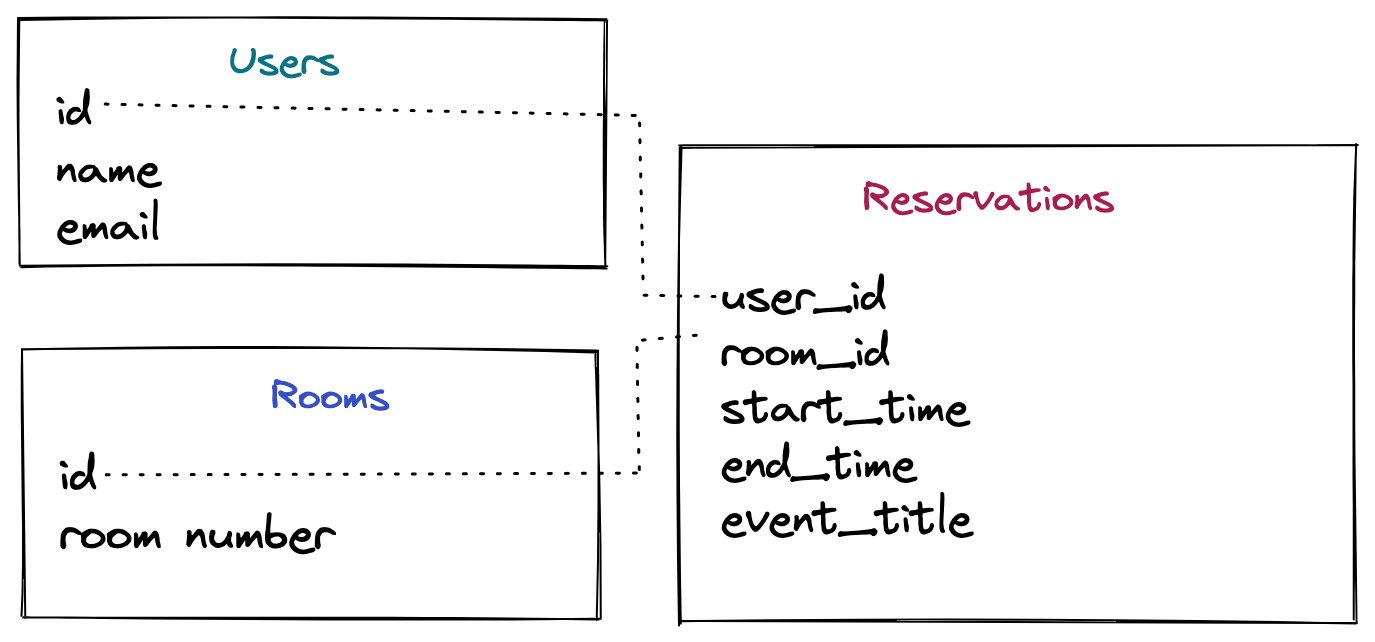
We will keep the first two tables (users and rooms) simple and create them without any constraints, let’s add this:
CREATE TABLE users (
id serial PRIMARY KEY,
name text,
email text
);
CREATE TABLE rooms (
id serial PRIMARY KEY,
number text
);
Foreign Key Constraints
To add the 3rd table which will reference these primary keys, we’ll use the
foreign key constraint. This is the references table(column) part of the first
2 lines.
CREATE TABLE reservations (
user_id int references users(id),
room_id int references rooms(id),
start_time timestamp,
end_time timestamp,
event_title text
);
Adding a foreign key constraint here is a really easy way to tie our reservations table to the other data tables ensuring they are always tied together with primary keys.
You can also add a foreign key constraints after the fact on an existing table
via ALTER TABLE. But you cannot edit a constraint with ALTER TABLE, you
have to drop and re-add the constraints.
In our case, since the foreign keys were added when the reservations table was
created, we need to drop them before we can use the ALTER TABLE command.
ALTER TABLE public.reservations DROP CONSTRAINT reservations_user_id_fkey;
ALTER TABLE public.reservations DROP CONSTRAINT reservations_room_id_fkey;
Now we can use ALTER TABLE to add back the constraint with the foreign key.
ALTER TABLE public.reservations
ADD CONSTRAINT reservations_room_id_fkey FOREIGN KEY (room_id) REFERENCES public.rooms(id);
ALTER TABLE public.reservations
ADD CONSTRAINT reservations_user_id_fkey FOREIGN KEY (user_id) REFERENCES public.users(id);
A foreign key constraint is named, see for example reservations_user_id_fkey. If you don't provide a name, Postgres will generate one for you.
Unique Constraints
Unique constraint is a setting that requires data in a certain column or row to be unique. This is particularly useful when creating usernames, unique identities, or any primary key. For example, we will want to put unique constraints on the room number so you don’t end up with a duplicate room number on accident:
ALTER TABLE ONLY public.rooms
ADD CONSTRAINT room_number_unique UNIQUE (number);
A unique key constraint is named, see for example room_number_unique. If you don't provide a name, Postgres will generate one for you.
Cascades & Foreign Keys
Foreign keys can also include definitions on how data is affected when changes
are made to linked tables. These are ON DELETE and ON UPDATE modifiers to
the foreign key constraint syntax.
Cascading deletes are particularly important if you’re required to delete user data for GDPR or other privacy requirements. For example, let’s assume in our schema that we want to delete users after a certain amount of time and we’re setting up some policies to do that. While we’re removing users, we also want to wipe their reservation history. Adding this constraint to the reservation data will delete the row in the reservation table if the user row is deleted.
ALTER TABLE public.reservations DROP CONSTRAINT reservations_user_id_fkey;
ALTER TABLE public.reservations
ADD CONSTRAINT reservations_user_id_fkey FOREIGN KEY (user_id) REFERENCES public.users(id) ON DELETE CASCADE;
If you do not provide the ON DELETE CASCADE, Postgres will prevent you from removing the record in the users table unless all reservation records for this user are removed first.
Note: Cascade statements must be added at the time the foreign key constraint is added. There’s no way to add a cascade after the fact via ALTER TABLE.
Not-null Constraints
In reviewing this data schema you’ll note places where you do not want null data. Adding a not-null constraint is a great way to ensure you’re never adding a row of incomplete data.
One example here would be making sure that all reservations have a start and end time:
ALTER TABLE public.reservations ALTER COLUMN start_time SET NOT NULL;
ALTER TABLE public.reservations ALTER COLUMN end_time SET NOT NULL;
Check Constraints
Check constraints are a great way to add some simple logic to your data by having the database check something before an insert. Check constraints will apply to a single row in a table. For example, in our schema we need to add some logic to our reservation's times. Start time should be less than the end time. Start time should be greater than 8am and less than 5pm. And that the interval between start time and end time is greater than 30 minutes.
Syntax for the check constraints
Start time is less than end time:
ALTER TABLE public.reservations ADD CONSTRAINT start_before_end CHECK (start_time < end_time );
Start time has to be greater than 8am, end time has to be less than 5pm.
ALTER TABLE public.reservations ADD CONSTRAINT daytime_check CHECK (start_time::time >= '08:00:00' AND end_time::time <= '17:00:00');
The interval between start time and end time is greater than 30 minutes.
ALTER TABLE public.reservations ADD CONSTRAINT interval_check CHECK (end_time - start_time >= interval '30 minutes');
Exclusion Constraints
Check constraints are great for comparing individual fields of a single record and ensuring that those are valid. If you want to check a row’s values against other rows in the same table, you need to use a more complicated method known as exclusion constraint. Exclusion constraints are used to define an expression returning a true/false result and only insert data if you get a false response. A true response will mean that this data already exists, so you can’t insert. A false response will mean the data does not yet exist and you can insert.
Common uses for constraint exclusions are adding roles for a user that can only have one role or adding a calendar reservation for someone that already has that time booked.
So before I get in too deep with the exclusion constraint, you’ll need to be expecting to use spatial data. Now why is that? Exclusion constraints commonly work with the idea that we have a box and that box is either filled in or not. And the box is sized based on the data points, like a time range. I know, it sounds a little wild to be getting into spatial data right now but this is just one of those Postgres tricks that has made its way into common practices. You’ll often see exclusion constraints using a GIST index. The GIST index will help Postgres query to see if this box is filled or not. We do not have to create the underlying index separately, creating the constraint will do that for us.
An exclusion constraint will probably have:
- EXCLUDE statement
- The GIST statement
- A box definition with points
- && which is an operator letting you know if a bounding box intersects another bounding box
And in our case here, some space between the boxes so they don’t overlap exactly. In my example I’ve added a subtraction in here for 0.5. Any number will work that is greater than 0 and less than one.
Here’s the syntax to create an exclusion constraint for reservation times so that no reservations are inserted that overlap with existing reservations.
ALTER TABLE public.reservations ADD CONSTRAINT reservation_overlap
EXCLUDE USING GIST (
box (
point(
extract(epoch from start_time),
room_id
),
point(
extract(epoch from end_time) - 0.5,
room_id + 0.5
)
)
WITH &&
);
Find the Constraints in your Database
If you need to look up what constraints you already have, this is a handy query which will show you all the types of constraints I've talked about so far:
SELECT * FROM (
SELECT
c.connamespace::regnamespace::text as table_schema,
c.conrelid::regclass::text as table_name,
con.column_name,
c.conname as constraint_name,
pg_get_constraintdef(c.oid)
FROM
pg_constraint c
JOIN
pg_namespace ON pg_namespace.oid = c.connamespace
JOIN
pg_class ON c.conrelid = pg_class.oid
LEFT JOIN
information_schema.constraint_column_usage con ON
c.conname = con.constraint_name AND pg_namespace.nspname = con.constraint_schema
UNION ALL
SELECT
table_schema, table_name, column_name, NULL, 'NOT NULL'
FROM information_schema.columns
WHERE
is_nullable = 'NO'
) all_constraints
WHERE
table_schema NOT IN ('pg_catalog', 'information_schema')
ORDER BY table_schema, table_name, column_name, constraint_name
;
Note that not null constraints are not named and will not appear in the
pg_constraints system table if you query the list of constraints. But they will
appear in this query since it joins in some of the table schema information.
Conclusion
- Take some time to think through Postgres’ full range of constraints when you’re setting up your schema.
- You’ll almost always want the foreign key constraints that ties together your primary keys.
- Make sure you add your cascades in at the beginning when you’re creating the foreign keys.
- If you run across bad data later, you can add constraints after the fact.