Advanced Crunchy Containers for PostgreSQL
Jeff McCormick
7 min readMore by this author
Crunchy Data is a leading provider of trusted open source PostgreSQL and PostgreSQL support, technology and training. In an earlier blog, the basics of the Crunchy PostgreSQL containers were presented demonstrating how easy and efficient it is to run PostgreSQL in containers such as Docker. In this follow up several new advanced features are highlighted from the Crunchy PostgreSQL for Kubernetes. The containers are open source and can be run either stand-alone, within Kubernetes, or within Red Hat's OpenShift Container Platform. The Crunchy Container Suite can be found here: https://github.com/crunchydata/crunchy-containers
Crunchy started working with Red Hat initially to spin up PostgreSQL containers and clusters. As we have gained experience working with PostgreSQL in containerized cloud native environments, we saw the need for a more complete PostgreSQL “toolbox”. This toolbox would allow for the administration and monitoring of deployed PostgreSQL containers. One of our goals with this container toolbox is to take advantage of container orchestration technology such as Kubernetes and OpenShift to also aide the DBA in managing a potentially large deployment of PostgreSQL instances.
Creating this set of PostgreSQL containers has required us to leverage advanced features of Kubernetes and OpenShift including Service Accounts, Jobs, and network persistent volumes.
The complete set of open sourced Crunchy PostgreSQL containers include:
- crunchy-postgres - runs PostgreSQL and also performs a backup restore
- crunchy-backup - performs a pg_basebackup on a database container
- crunchy-pgbadger - hosts a simple http server that executes pgbadger against a database container to produce HTML reports that provide detailed PostgreSQL log analysis
- crunchy-pgpool - provides a pgpool container that lets applications access a PostgreSQL cluster via a single connection
- crunchy-collect - collects 32 different PostgreSQL metrics from a database container and pushed them to a Prometheus time series data store
- crunchy-grafana - provides a web based graphing dashboard for collected PostgreSQL metrics
- crunchy-prometheus - provides a prometheus datastore for metrics collection
- crunchy-pgbouncer - provides a simple form of automated failover as well as basic pg_bouncer connection pooling
- crunchy-watch - provides a form of automated failover by watching a PostgreSQL cluster’s master and triggers a failover on a slave if the master is not responding
These containers are pre-built and can be found on DockerHub.
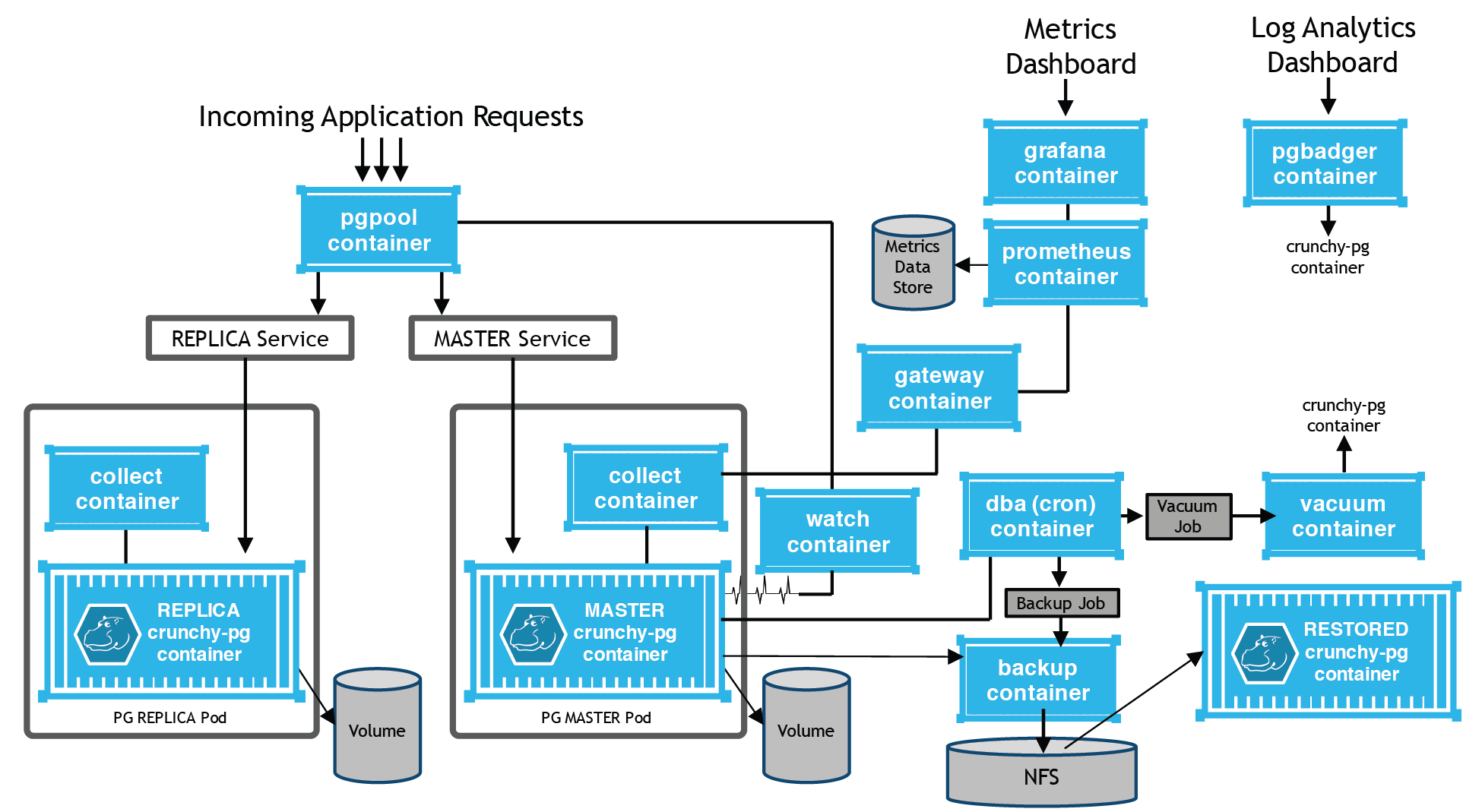
Some containers are in development and not open sourced at this time, they include:
- crunchy-dba - provides a cron scheduler for executing vacuum and backup jobs
- crunchy-vacuum - provides a microservice for running PostgreSQL vacuum commands
- crunchy-ui - administrative user interface
In the following sections we will discuss some of these container features.
Performing a Full Database Backup
Backups are performed as a Kubernetes job. A job is meant to be a one-time execution of something, similar to a batch job. Within the crunchy-backup container, the PostgreSQL backup utility, pg_basebackup, is executed on an existing database container.
Environment variables for the crunchy-backup container are used to specify the database for which a backup is performed as well as the database credentials to use for the backup.
Backups require a persistent volume type such as NFS be mounted by the backup job. The first steps in using the backup container are to create a Persistent Volume (PV), and then the Persistent Volume Claim (PVC). The Openshift backup job example is found here.
Backups are stored using a naming convention as follows:
/nfsfileshare/container-name/timestamp
You can keep as many backups as your file system will allow and the contents of the backup directory are left for your operations team to manage using normal file system procedures.
Performing a Database Restore
Within the crunchy-postgres container is a restore feature. When crunchy-postgres begins executions, it looks for a specified backup archive location. If found, it will use the backup archive, from the pg_basebackup utility, to base a new database upon. The restore feature uses the rsync utility to copy the backup archive files from the NFS directory to the /pgdata volume used by the new database container.
An example of restoring from a database archive is found here. The BACKUP_PATH environment variable is used by the crunchy-postgres container to specify the database backup archive location to use for a restore.
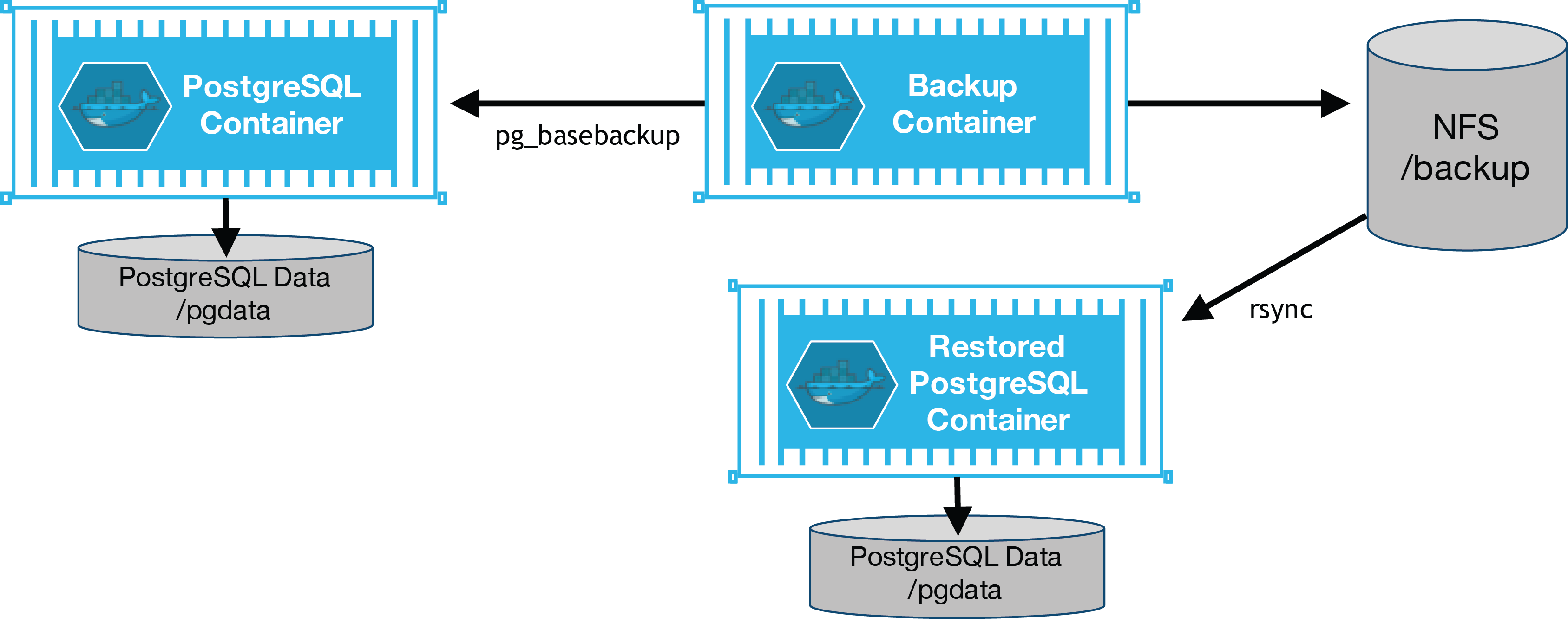
Fig. 1 Backup and Restore
Creating PGbadger Reports
PostgreSQL database administrators often use a popular utility called pgbadger to examine the logs of a PostgreSQL database. The pgbadger utility is written in Perl and is a command line utility which reads the PostgreSQL log files and generates a HTML/Javascript output file that containers graphs and detailed analysis.
The crunchy-pgbadger container provides a small http server (in golang) which you can invoke which will in turn invoke pgbadger. The pgbadger output file is then served back to the user via the http service.
You simply place the crunchy-pgbadger container within a database pod and you now have a pgbadger microservice that you can invoke from your browser.
There is an example of using crunchy-pgbadger here.
Browse to the pgbadger endpoint using http://<pod-name>:10000/api/badgergenerate
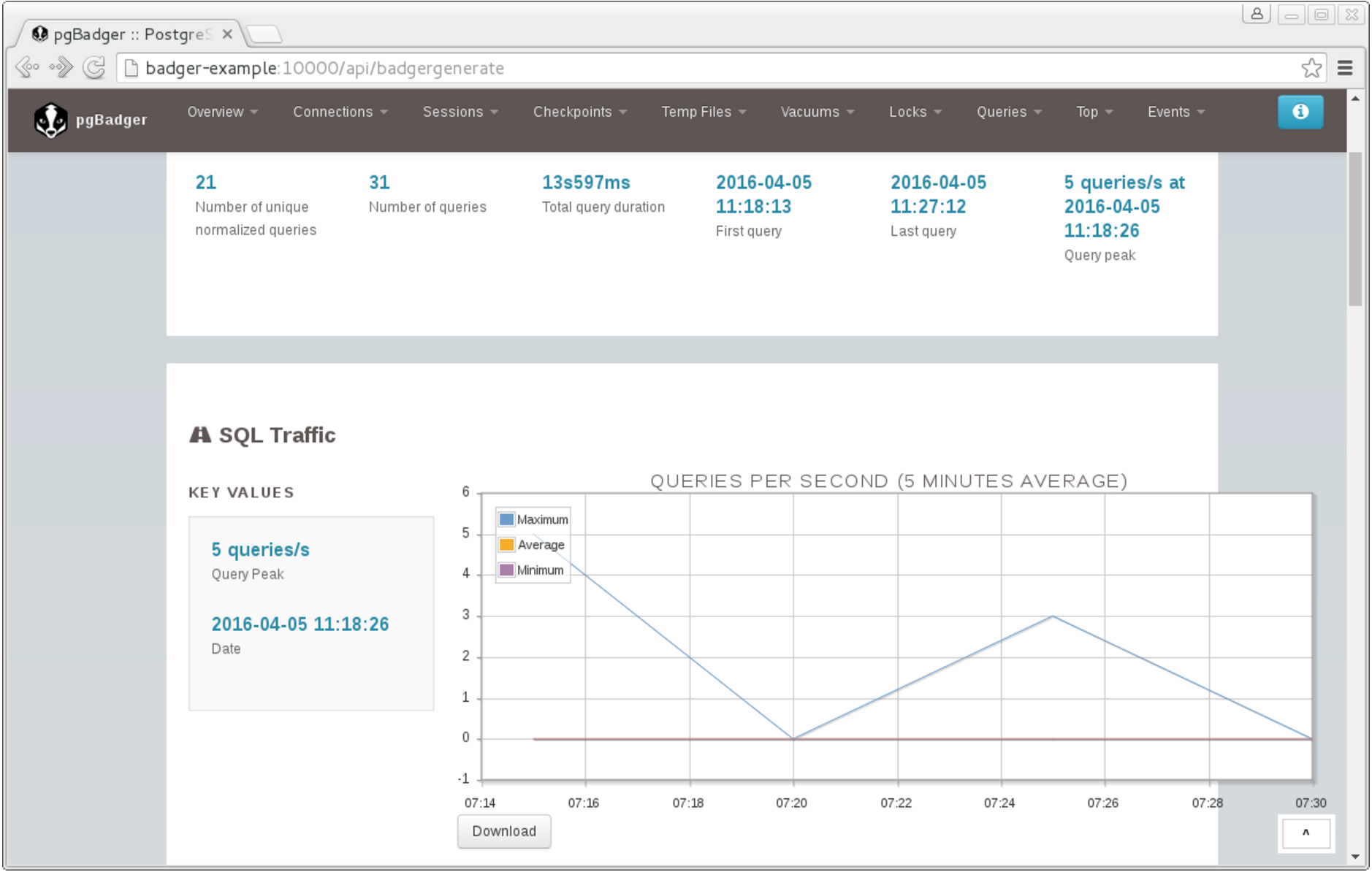
Fig. 2 pgBadger Output
Performing a Failover
A PostgreSQL cluster is a replication configuration where a master replicates to a number of slaves. If you lose the master due to a hardware failure or any other reason, you can cause one of the slaves to take over the master’s responsibility. One means of causing this failover is to create a predefined trigger file on the slave, after which, the PostgreSQL server will alter its configuration to become a read-write master database.
The crunchy-watch container is meant to watch a given master and test whether the master can be reached or not. If not, crunchy-watch will create a trigger file on the first slave it finds. Crunchy-watch also changes the slave’s Openshift labels to that of the master. This way, the clients will find the new master using the existing master service as before.
After a failover, the crunchy-watch will continue to watch the new master for a failure as before the first failover.
The crunchy-watch container makes use of a Service Account to send commands to Openshift such as getting a list of pods or changing the label of a pod.
A failover example is found here. Within the example, you would specify your master and slave service names. Deletion of the master pod will initiate a failover.

Fig. 3 High Availability with Crunchy-watch
Collecting Metrics
Collecting PostgreSQL metrics allows a database administrator a means of looking at trends of data and resource usage within a database. The crunchy-collect container can be placed within a database pod to begin the collection of 30+ PostgreSQL metrics. An example of a pod that includes the crunchy-collect container is here.
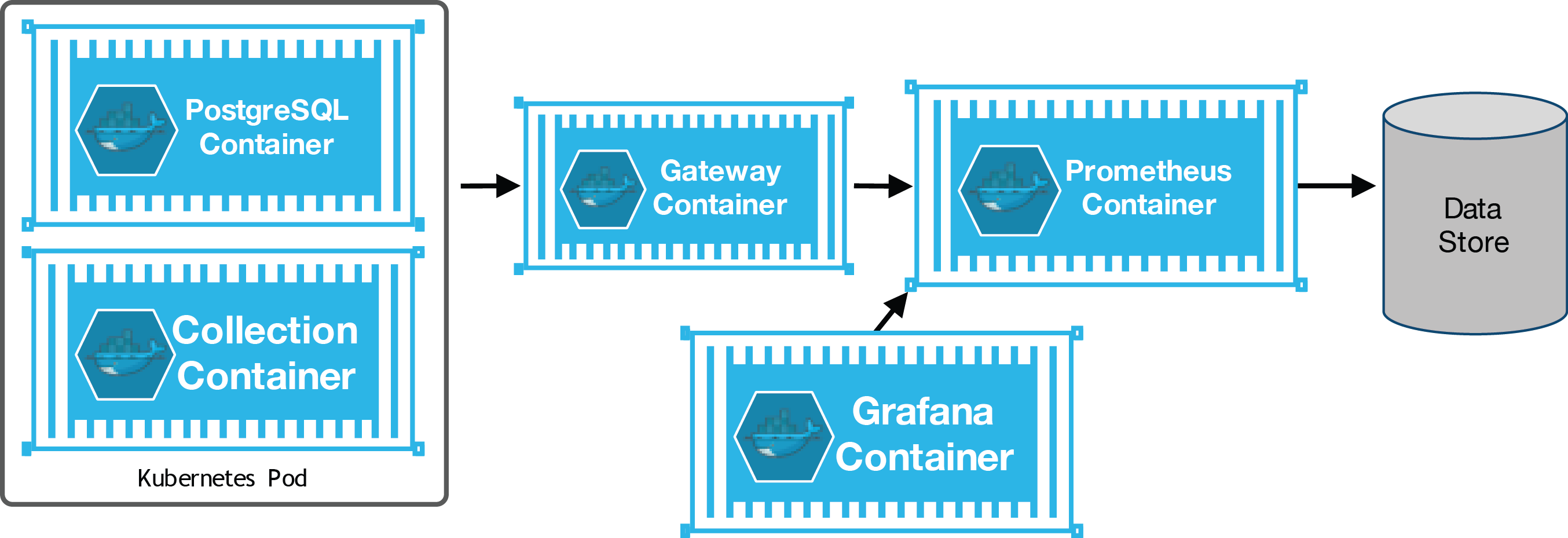
Fig. 4 Metrics Collection
The collected metrics are pushed to the crunchy-prometheus container using the prometheus push gateway. Metrics are stored within a prometheus time-series database.
The grafana graphing product is included in the crunchy-grafana container. Both the prometheus database and the grafana web application are started within the crunchy-metrics pod as found here.
Fig. 5 Grafana Dashboard for Monitoring
Next Steps
These advanced features were provided to allow enterprise customers the ability to perform basic administration tasks common to running a PostgreSQL database or cluster. Over the coming months, more advanced features are planned for addition within the Crunchy Containers suite. Our goal is to build not only a great PostgreSQL container but also an entire set of microservices geared towards managing and monitoring your deployed PostgreSQL containers.
About Crunchy Data
Crunchy Data is a leading provider of trusted open source PostgreSQL and PostgreSQL support, technology and training. Crunchy Data is the provider of Crunchy Certified PostgreSQL, an open source PostgreSQL 9.5 distribution including popular extensions such as PostGIS and enhanced audit logging capability. Crunchy Certified PostgreSQL has received the international Common Criteria certification at the EAL2+ level, making Crunchy Certified PostgreSQL the only 100% open source RDBMS with Common Criteria certification.
When combined with Crunchy’s Secure Enterprise Support, Crunchy Certified PostgreSQL provides enterprises with an open source and trusted relational database management solution backed by enterprise support from leading experts in PostgreSQL technology. For enterprises requiring dedicated PostgreSQL support, Crunchy provides on-premise PostgreSQL professional services and PostgreSQL training. Learn more at www.crunchydata.com.
Related Articles
- Hybrid Search Patterns with Postgres and pgvector
13 min read
- Postgres 19 Compression: from pglz to LZ4
8 min read
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read