Avoiding the Pitfalls of BRIN Indexes in Postgres
John Porvaznik
10 min readMore by this author
Postgres has a number of different index types. You’ve got B-Tree, GIN, GiST, Sp-GiST, and BRIN. BRIN is a lightweight index that often goes misunderstood. When implemented correctly, it offers significant benefits such as space savings and speed. However, when implemented incorrectly, it loses some of its benefit, so it's important to look at some of the reasons a BRIN index might not be right for you.
BRIN Overview
A BRIN is a Block Range Index. A block is Postgres’ base unit of storage and is by default 8kB of data. BRIN samples a range of blocks (default 128), storing the location of the first block in the range as well as the minimum and maximum values for all values in those blocks. It’s very useful for ordered data sets, offering significant space savings for similar and sometimes better performance.
BRIN has been talked about in depth in many other blog posts. See this post for even more information.
About our test data
Test data was created to emulate in-order sensor data, with a random sampling of five values with the following SQL:
insert into test (ts,value) (select generate_series('2010-01-01
00:00:00-05'::timestamptz, ('2010-01-01 00:00:00-05'::timestamptz +
'999999 seconds'::interval), '1
second'::interval),(array['foo','bar','baz','qux','quux'])[floor(random() * 5 + 1)]);
BRIN Structure
Postgres stores indexes similar to tables. We can view our BRIN index as rows and columns with the help of the pageinspect extension. A full review of pageinspect is beyond our current scope, but we can use the query below to return the first two records of our index.
select blknum, value from brin_page_items(get_raw_page('test_brin_idx',5),'test_brin_idx')
order by blknum limit 2;
| blknum | value |
|---|---|
| 0 | {2010-01-01 00:00:00-05 .. 2010-01-01 05:34:55-05} |
| 128 | {2010-01-01 05:34:56-05 .. 2010-01-01 11:09:51-05} |
These results show how a BRIN index profiles our database pages. They are created by looking at the records as they are in the table.
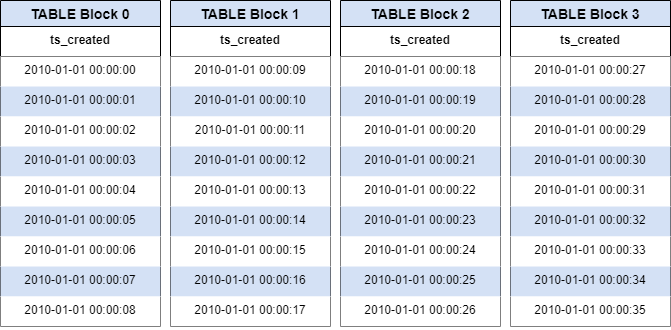
These records are then scanned for the bounding values for some number of pages. By default this is 128 pages, but it can be set at index creation time by passing a different value to pages_per_range.
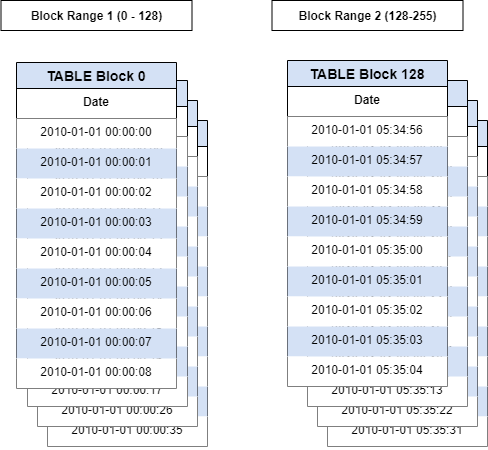
This condensed sampling results in a much smaller number of rows in the index to rows in the table. We can calculate those values with some help from the pg_catalog.
First we get the number of pages/blocks for our table:
select relpages from pg_class where relname = 'test’;
| relpages |
|---|
| 6370 |
Then we get our table count:
select count(*) from test;
| count |
|---|
| 1000000 |
And with a little bit of math (
Unlike a Btree index, BRIN does not provide us with a direct pointer to the record in the table, it instead points to a page offset. This means that for any hit on a BRIN index, we need to read through all the blocks in the provided range. There is a balance of efficiency between reading all of a much smaller BRIN index at the cost of reading many table blocks vs navigating a smaller portion of a much larger index to get a direct pointer to your record.
Size vs. Speed
We can examine what those index size differences and searches are at various table sizes.
Our test data is created emulating sensor data. We generate a record per second with a random text value. Multiple selects were performed for each table and each select type keeping rounded averages after removing outliers. Note that the timing values should be viewed as "directional:" these can fluctuate based on your underlying hardware, configurations at different levels of the stack, etc.
Btree vs. BRIN index at various table sizes:
| Records | Table Size | BTREE Size | BRIN Size |
|---|---|---|---|
| 1,000 | 88kB | 40kB | 4kB |
| 10,000 | 544kB | 240kB | 48kB |
| 100,000 | 5.1MB | 2.2MB | 48kB |
| 1,000,000 | 50MB | 21MB | 48kB |
| 10,000,000 | 498MB | 214MB | 56kB |
| 100,000,000 | 4.9GB | 2.1GB | 208kB |
| 1,000,000,000 | 49GB | 21GB | 1.7MB |
BTree vs. BRIN select speeds at various table sizes:
At a glance, we can see:
- BRIN’s space savings over Btree are significant.
- Btree generally outperforms BRIN for single record queries.
- The query planner didn't even consider the BRIN index until we had at least 100k records.
- BRIN performs better comparatively when looking for more records.
When should we use BRIN
We can make some generalizations about when to use a BRIN index from these results, but experience and deeper understanding of the index itself helps flesh it out.
Use BRIN when we have a large insert-only in-order table with large select results.
In the database world where every answer starts with ‘it depends’, this is about as straightforward an answer as you can get. But it also includes a lot of specificity.
Each of the modifiers (large, insert-only, and in-order) warns against some of the pitfalls of blindly adopting BRIN.
LARGE
We can see in our case that the query planner doesn’t even consider the BRIN index until the table is 100k records large, and doesn’t match our BTREE index until the table is around 1 million records large.
With large selects, we observe that a single-record selects are well out-performed by Btree indexes. If our data-access is centered around quick single record retrieval, a btree may be the better answer.
IN-ORDER
BRIN relies heavily on data adjacency (similar data is found near each other on disk). If our data is out of-order, there's a higher chance that our BRIN ranges will overlap. Once your BRIN ranges start to overlap, you’ll start to match multiple BRIN records, and need to read from multiple block ranges from the source table to find the record we're looking for.
Consider if our original data wasn't inserted in order, our BRIN from the top of the page might now look like this.
| blknum | value |
|---|---|
| 0 | {2010-01-01 00:00:00-05 .. 2010-01-01 11:09:45-05} |
| 128 | {2010-01-01 00:00:05-05 .. 2010-01-01 11:09:51-05} |
Notice that the lower bound of our second record is now lower, and our upper range of our first record is now higher. Both ranges would now match a select for '2010-01-01 01:00:00', causing the backend to require reading both sets of blocks. In this instance, this doubles our reads on the table.
What to look out for
It’s all about how you insert your data. Even when you receive data in order, there’s many ways to insert it out of order.
Parallel processing: Multiple processes that insert into the same table. If I receive 12 months of data, and create 12 insert processes, and insert one-record-at-a-time, there’s a good chance that every block will have data from every month. This reduces both the adjacency of the data, and the selectivity.
Manual entry: Our clerk doing manual data entry dropped the sheets of pages, now they’ve entered page 14 before page 1.
Batch ETL out of order: Most batch ETL runs dozens to thousands of inserts at a time, and most are well engineered to be in-order, except when they’re not. If every 100 files or so, our batch processor misses a file, and then retries it 1 hour to 1 day later (after another 100 files have been inserted), it has the same effect as manual entry being out of order.
Received the data late: Your vendor usually delivers data on time, but Monday’s data got lost in the mail. So you processed the rest of the week. On Friday they finally get you Monday’s data, at which point if you insert it, your inserts will be out-of-order.
What to do about it
In general, be aware of it, and how often ‘exceptions to the rule’ happen. The cleanliness of your test environment doesn’t always stand up against the realities of production.
INSERT-ONLY
Updates and deletes change the data in a block. These concepts can be a bit confusing, so we can look at them more in-depth with illustrations.
An illustrated guide to how inserts and deletes affect a BRIN Index
Our initial data set includes the numbers 1-18 across three blocks.

Each header represents a BRIN record: a block pointer and our range associated with that block. Our three columns include two ‘invisible’ columns that are used internally for ‘reuse’ and ‘deleted’ as well as our record.
Deletes
In Postgres, a delete doesn’t actually remove the record from the table. Instead, it marks a record as deleted. This preserves that record for any older transactions that might still need that data. It is the vacuum process’ job to identify and clean up deleted records. The specifics are a bit more complex, and if you’re interested you should search for articles on Postgres MVCC.
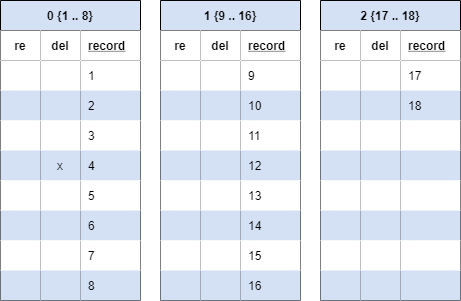
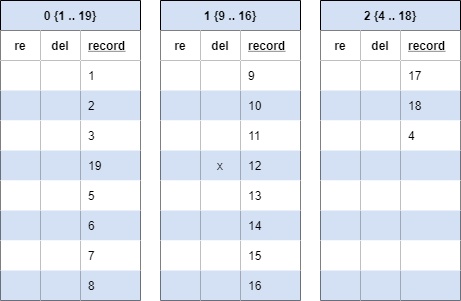
We've deleted 4, note the mark in the 'del' column. We haven’t removed the number 4 from the record column because that value may still be visible to some older transactions. At some point a manual vacuum or the autovacuum process will come along and clean up the record.
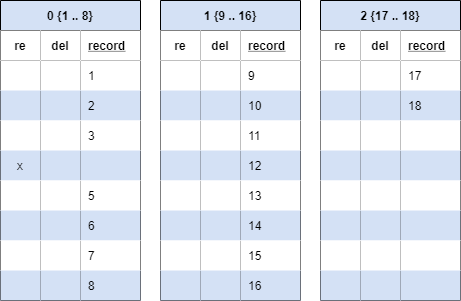
4 is now gone.
If we select for 4, our BRIN index will give us a hit directing us to look in block 0 (4 is between 1 and 8). We would then need to scan all the records in block 0 to find the value 4. Finding nothing, we would return an empty set.
Insert after delete
Later we insert a new record. 19 is inserted where 4 was previously. Additionally, our BRIN has been updated as indicated by the new header. The new bounds for block 0 are 1-19.
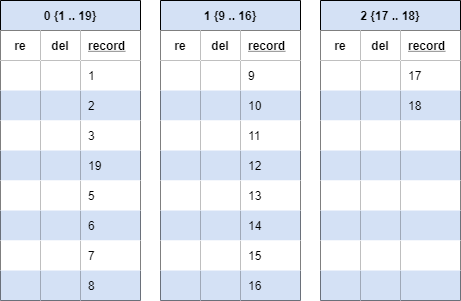
Block 0 now has a range that covers the entire table.
That means that any select will require reading block 0. For example, if we select for 17, our BRIN index directs us to blocks 0 and 2. We will then scan the values in both of blocks 0 and 2, eventually finding 17 in block 2 and returning our single record.
Updates
An update is as simple as an insert closely coupled with a delete. An update does not change a value in place. It first inserts the new value in the first available space, then marks the old record as deleted.
We’ve updated 12 to 4 below.
After our update, 4 is at the end of the table in block 2 and 12 is marked deleted. Our BRIN ranges have all also been updated. We now have three overlapping blocks, and block 1 is fully within the ranges for blocks 0 and 2.
If we were to select 12, our BRIN would direct us to read block 0, 1, and 2. After reading all three blocks, we would be returned an empty set since 12 is marked as deleted.
Delete/Update -- Not even once
Deletes and updates can drastically alter your tables and as a result, your BRIN. Even operations on single records have the potential to change the table profile.
The below table shows how our queries perform after performing a delete-vacuum-insert. This was done by deleting ~20% of the table (by selecting one of our five random values), vacuuming, and finally inserting the new records equal to the number of deleted records. Selects were then performed against this data
BRIN select speed after ~20% delete and ~20% insert:
The results speak for themselves. It shows that there is significant query slow down after delete + insert. Additionally, the query speeds when testing against the 100 million record table were so varied that it would be unfair to create an average across that variance. It’s also interesting to note that after our delete and insert, the results in the 100 million record table took the same amount of time without regard to how many records were requested.
BRIN isn’t all bad
BRIN is great... until it isn’t. The pattern usually follows that a BRIN implemented in a clean test or dev environment solves every problem. But once it’s implemented in production, where one-off updates, or out-of-order ETL occur, it fails to live up to previous expectations. This is why a full evaluation of what might happen needs to be done before relying too heavily on something as delicate as BRIN.
Related Articles
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read
- PostGIS Performance: Simplification
3 min read
- How to Read Postgres EXPLAIN: A Guide to Scan Types
9 min read