Easy PostgreSQL Cluster Recipe Using Docker 1.12 and Swarm
Jeff McCormick
6 min readMore by this author
UPDATE
PLEASE READ THE UPDATED VERSION: AN EASY RECIPE FOR CREATING A POSTGRESQL CLUSTER WITH DOCKER SWARM
The below content has been deprecated in favor of An Easy Recipe for Creating a PostgreSQL Cluster with Docker Swarm.
Deprecated Recipe
In this blog I’ll show you how to deploy a PostgreSQL cluster using the latest Docker 1.12 technology. Updates to Docker in their 1.12 release greatly simplify deploying a PostgreSQL cluster. IP addresses and hostnames used in this blog are just examples and not mandated.
Recipe Step 1 - Environment
To start with, provision a Docker cluster. For this example, I have deployed a development cluster that looks like this:
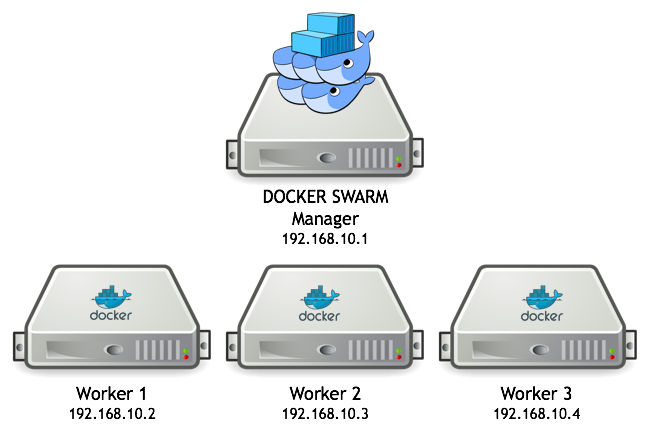
Each host has Docker 1.12 installed and enabled.
Recipe Step 2 - Swarm Setup
Docker 1.12 now includes the Swarm clustering technology directly within the Docker Engine. On your Docker 1.12 cluster, you will need to configure Swarm as documented here:
https://docs.docker.com/engine/swarm/swarm-tutorial/create-swarm
This setup will include initializing Swarm on the Manager designated node using:
docker swarm init --advertise-addr 192.168.10.1
Then on the other Docker worker nodes you would enter this command for them to join the Swarm:
docker swarm join --token SWMTKN-1-65cn5wa1qv76l8l45uvlsbprogyhlprjpn27p1qxjwqmncn37o-015egopg4jhtbmlu04faon82u 192.168.10.1:2377
Recipe Step 3 - Docker Network Setup
Docker 1.12 also includes the ability to define an overlay network to be shared by a set of containers, again this feature is directly built into the Docker Engine. For this PostgreSQL cluster example, we create an overlay network (on the manager node), named crunchynet, as follows:
docker network create --driver overlay crunchynet
This overlay network will provide us a means to perform service discovery between the PostgreSQL replica containers and the PostgreSQL master container. In PostgreSQL streaming replication (clustering), the replica containers need to be able to locate a master database by either IP address or a hostname that will resolve via DNS. The Docker overlay network provides this lookup capability for us if the PostgreSQL containers are all connected to the same overlay network. Within the overlay network, Docker will allow us to resolve the PostgreSQL host using the Docker service name.
Recipe Step 4 - Container Placement
For a highly available PostgreSQL cluster configuration you would want the master database to run on a different host than where the replica databases will be run. Also, you might have a particular host you want the master container to be running on since it will be providing a write capability. Remember, in a PostgreSQL cluster, replica databases are read-only, whereas the master is read-write. So, you might want the master container to be placed on a host with a very fast local disk performance capability.
To allow for container placement, we will add a metadata label to our Swarm nodes as follows:
docker node inspect worker1 | grep IDdocker node update --label-add type=master 18yrb7m650umx738rtevojpqy
In the above example, the worker1 node with ID 18yrb7m650umx738rtevojpqy has a user defined label of “master” added to it. The master service specifies “master” as a constraint when created, this tells Swarm to place the service on that specific node. The replica specifies a constraint of “node.labels.type != master” to have the replica always placed on a node that is not hosting the master service.
Recipe Step 5 - PostgreSQL Cluster Startup
Finally, we have all the wiring and configuration in place to start running our PostgreSQL cluster. Docker 1.12 provides the service abstraction around the underlying deployed containers. This is a powerful abstraction in that it provides a higher-level form of identifying and deploying your application containers across a set of Docker Swarm hosts.
Our PostgreSQL cluster will be comprised of a PostgreSQL master service and a PostgreSQL replica service. Services are created by running the following commands on the Swarm manager node:
docker service create \
--mount type=volume,src=$MASTER_SERVICE_NAME-volume,dst=/pgdata,volume-driver=local \
--name $MASTER_SERVICE_NAME \
--network crunchynet \
--constraint 'node.labels.type == master' \
--env PGHOST=/tmp \
--env PG_USER=testuser \
--env PG_MODE=master \
--env PG_MASTER_USER=master \
--env PG_ROOT_PASSWORD=password \
--env PG_PASSWORD=password \
--env PG_DATABASE=userdb \
--env PG_MASTER_PORT=5432 \
--env PG_MASTER_PASSWORD=password \
crunchydata/crunchy-postgres:centos7-9.5-1.2.5
Then create the replica service as follows:
docker service create
--mount type=volume,src=$VOLUME_NAME,dst=/pgdata,volume-driver=local \
--name $SERVICE_NAME \
--network crunchynet \
--constraint 'node.labels.type != master' \
--env PGHOST=/tmp \
--env PG_USER=testuser \
--env PG_MODE=slave \
--env PG_MASTER_USER=master \
--env PG_ROOT_PASSWORD=password \
--env PG_PASSWORD=password \
--env PG_DATABASE=userdb \
--env PG_MASTER_PORT=5432 \
--env PG_MASTER_PASSWORD=password \
--env PG_MASTER_HOST=$MASTER_SERVICE_NAME \
crunchydata/crunchy-postgres:centos7-9.5-1.2.5
After running these commands, you will end up with a deployment of containers as depicted in this diagram:
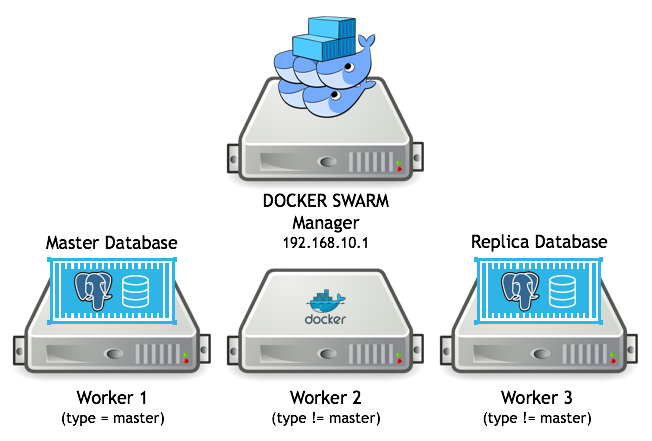
Note the following lines from the examples above when creating the Docker services:
--constraint 'node.labels.type == master'
This line supplies a constraint to the Swarm manager when choosing what Swarm node to run the container, in this case, we want the master database container to always run on a host with the master label type, in our case this is the worker1 host.
--network crunchynet
This line specifies the network we want the container to use, in our case the network is called crunchynet.
--mount type=volume,src=$VOLUME_NAME,dst=/pgdata,volume-driver=local
This line specifies a dynamically created Docker volume be created using the local driver and which will be mounted to the /pgdata directory within the PostgreSQL container. The /pgdata volume is where PostgreSQL will store it’s data files.
--env PG_MASTER_HOST=$MASTER_SERVICE_NAME
This line specifies the master PostgreSQL database host and in this case is the Docker service name used for the master database service. This name is resolved by means of the overlay network we created, crunchynet.
Recipe Step 6 - Testing the Cluster
Docker 1.12 provides the service abstraction around the underlying deployed containers. You can view the deployed services as follows:
docker service ps master
docker service ps replica
Given the PostgreSQL replica service is named replica, you can scale up the number of replica containers by running this command:
docker service scale replica=2
docker service ls
You can verify you have two replicas within PostgreSQL by viewing the pg_stat_replication table, the password is password, when logged into the kubernetes-node-1 host:
docker exec -it $(docker ps -q) psql -U postgres -c 'table pg_stat_replication' postgres
You should see a row for each replica along with its replication status.
Example Code
The example described above is provided in the Crunchy Containers Suite github in the following location:
https://github.com/CrunchyData/crunchy-containers/tree/master/examples/docker/swarm-service
Conclusion
The update to Docker with the 1.12 release contains an impressive set of new features that greatly simplify enterprises in deploying PostgreSQL to their container environments. I look forward to other enterprise container features being added to the Docker engine including a distributed storage implementation.
Jeff McCormick, the author, works for Crunchy Data, a leading provider of enterprise open source PostgreSQL technology, support and training.