PostgreSQL Operator for Kubernetes
Jeff McCormick
5 min readMore by this author
Crunchy Data is pleased to announce an initial implementation of a PostgreSQL Operator for Kubernetes to build on our work with PostgreSQL Containers. This initial implementation provides a user with the ability to perform certain PostgreSQL functions including creating PostgreSQL clusters, performing database backup and restores and viewing persistent volume claims.
Operators
Last November the team at CoreOS introduced the concept of an “application-specific controller” for Kubernetes called software Operators. In their announcement, CoreOS suggested Operators as a means to more efficiently manage database infrastructure.
Crunchy Data has previously released a suite of containers for deploying, administering and monitoring PostgreSQL and leveraging the Operator concept to further advance the deployment and management of PostgreSQL functions within Kubernetes was a natural extension of our work to date.
To that end, Crunchy Data is pleased to announce an initial implementation of a PostgreSQL Operator.
Initial Scope
For the initial release of a PostgreSQL operator our team has focused on a few basic operations that a user would interact with on a daily basis including:
- View existing databases and clusters
- Create a single master or master-replica PostgreSQL configuration
- Delete a single master or entire PostgreSQL deployment
- Perform a database backup and list prior backups
- Perform a database restore
- Provide visibility into a Persistent Volume Claim
Design Features
The Operator concept makes use of Third Party Resources (TPR) to create a set of domain specific objects that pertain to a specific application. This Operator creates PostgreSQL specific objects, including: pgdatabase, pgcluster, and pgbackup. A few additional notes on the design:
- The PostgreSQL Operator runs in a Deployment on the Kubernetes cluster and watches for TPR events
- The user interface of the PostgreSQL Operator is a command line utility called
pgo - The PostgreSQL Operator allows for a variety of Persistent Volume technologies to be used such as HostPath, NFS, and block storage.
- The PostgreSQL Operator allows for different deployment strategies to be defined. A Deployment Strategy in the case is the set of objects that the Operator will create for a new database or PostgreSQL cluster including Pods, Services, Deployments, etc. This is a key feature in that different customers will want to customize exactly how their PostgreSQL databases are deployed.
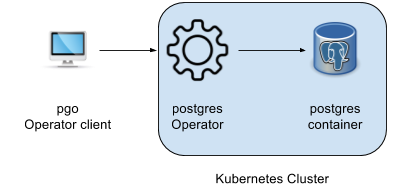
The following diagram shows the pgo client communicating to the Postgres Operator running within the Kubernetes Cluster and causing the Operator to create or act upon PostgreSQL containers.
Source Code
The PostgreSQL Operator is primarily written in golang and available on GitHub. Instructions on building the code is found under the heading Build-Setup Documentation.
A binary release is provided along with the requisite Docker images on Docker Hub.
Getting Started
In order to get started, a user can build a single master PostgreSQL database using the pgo command line utility as follows:
pgo create database mydatabase
This command creates a database TPR upon which the Operator will act. This command will cause the PostgreSQL Operator to use the default database deployment strategy and create a Pod running the PostgreSQL database along with a Service mapped to the database pod.
A user can then view the database using the following command:
$ pgo show database mydatabase**
database : mydatabase**
├── pod : mydatabase (Running)**
└── service : mydatabase (10.108.0.81)
Once the database is created, a user can perform a database backup using the following command:
pgo create backup mydatabase
This command will create Kubernetes Job that executes a full database backup on the previously created PostgreSQL database named mydatabase.
The following command allows a user to view the backup:
$ pgo show backup mydatabase
pgbackup mydatabase was found PVC_NAME is crunchy-pvc
backup job pods for database mydatabase...
└── backup-mydatabase-63fw1
└── mydatabase
database pod mydatabase is found
├── mydatabase-backups/2017-03-27-13-54-33
├── mydatabase-backups/2017-03-27-13-56-49
└── mydatabase-backups/2017-03-27-14-02-38
Once the backup has been created, it is possible to create a database off of that backup using the following command:
$ pgo create database myrestoredb
--backup-path=mydatabase/2017-03-27-14-02-38 --backup-pvc=mydatabase-pvc
Deploying a PostgreSQL Cluster
Lastly, lets create a more complex PostgreSQL cluster:
pgo create cluster mycluster
This command creates a master database deployment, replica database deployment, a service for the master, and a service for the replicas.
$ pgo show cluster mycluster**
cluster : mycluster
├── deployment : mycluster
├── deployment : mycluster-replica
├── replicaset : mycluster-2460202476
├── replicaset : mycluster-replica-306362430
├── pod : mycluster-2460202476-ndndb (Running)
├── pod : mycluster-replica-306362430-blzvd (Running)
├── pod : mycluster-replica-306362430-s32g7 (Running)
├── service : mycluster (10.107.139.100)
└── service : mycluster-replica (10.100.198.149)
Finally, it is possible to delete of all of the databases created using the following command:
pgo delete database mydatabase
pgo delete cluster mycluster
Conclusion
The Third Party Resource API and golang client projects are both emerging frameworks that let allow application providers like Crunchy Data to build a rich native orchestration layer for Kubernetes In our case, our orchestration is focused on the PostgreSQL database but the pattern and frameworks could certainly be applied to other applications.
In particular, the Operator concept provides an exciting new platform Crunchy Data looks forward to build on and further advances our objective of saving users time in deploying and managing container based PostgreSQL databases infrastructure. This blog provides an discussion of an initial set of PostgreSQL Operator functions. Crunchy Data plans to continue our development to offer more extensive and advanced PostgreSQL automation in future versions of the PostgreSQL Operator, so please stay tuned!