Using Kubernetes? Chances Are You Need a Database
4 min readMore by this author
Whether you are starting a new development project, launching an application modernization effort, or engaging in digital transformation, chances are you are evaluating Kubernetes. If you selected Kubernetes, chances are you will ultimately need a database.
Kubernetes provides many benefits for running applications including efficiency, automation, or infrastructure abstraction. These features allow you to deploy highly availability databases and scale, making it easier to manage hardware for databases as they grow.
More users are adopting databases on Kubernetes. The Cloud Native Computing Foundation (CNCF) provides great data on Kubernetes adoption. The Cloud Native Survey 2020 that 55% of respondents are using stateful applications in containers in production. Crunchy Data has many customers who successfully run Postgres on Kubernetes.
So how do you start with databases on Kubernetes?
Selecting Your Database
As users select new databases for Kubernetes, they generally start with open source. Typically users adopt a combination of SQL and NoSQL databases for their data toolbox.
At Crunchy Data, we are fans of Postgres and believe it is a great fit for SQL workloads on Kubernetes. We are happy to see the CNCF agree with this assessment. The CNCF End User Technology Radar for Database Storage places Postgres in the "Adopt" category. This status indicates Postgres is among "widely adopted and recommended by the respondents."
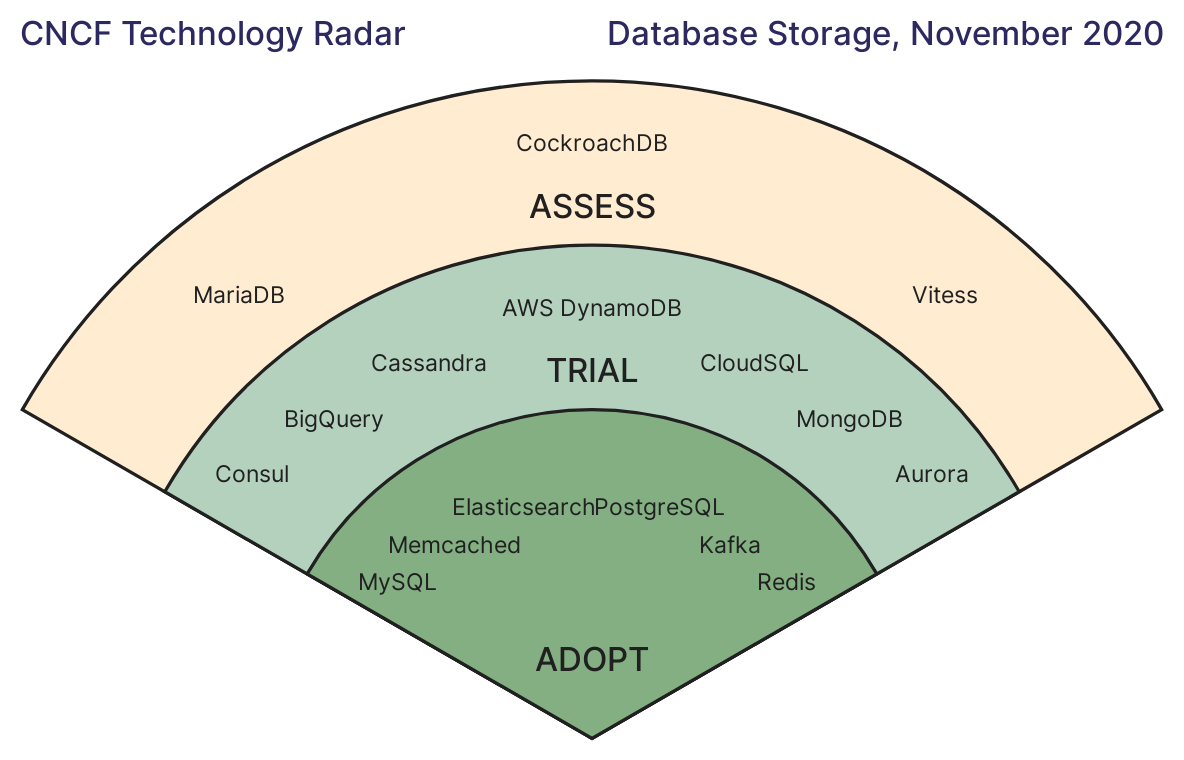
With the right tools (like PGO, the Postgres Operator from Crunchy Data) and expertise, Postgres is Kubernetes friendly.
You Probably Want an Operator
The term “operator” was a term coined by CoreOS. Technically, a Kubernetes Operator is an application-specific controller for Kubernetes. Simply put, an operator is a Kubernetes extension to automate actions of a human "operator".
The operator pattern works especially well for databases, which can be admin intensive. Tasks like backups or restore typically need human intervention. A database operator can automate these administrative tasks, reducing your admin burden. Application specific operators go a step further to provide application specific automation which can accelerate scaling and standardization.
For instance, PGO automates Postgres specific capability through automating Postgres tools and expertise. PGO provides GitOps friendly workflows for provisioning standardized Postgres clusters and automates high availability, disaster recovery, and monitoring.
You can use an operator in a range of use cases. Users can deploy Kubernetes native applications alongside Postgres using PGO. Operators provide centralized administrations and automation at scale for users building a database-as-a-service.
Storage Options
Databases are different than stateless apps in that they need persistent storage.
Databases running on Kubernetes can make use of a range of storage types. Options include HostPath, Network File System (NFS), and Dynamic storage. PGO is storage agnostic: it works with any supported Kubernetes storage system.
You must provision persistent volumes for both Hostpath and NFS, though automated storage provisioners do exist. Dynamic storage classes allow users to request persistent volume claims and have the persistent volume created for you. There are many providers of dynamic storage classes to choose from. You will need to configure what works for your environment and size the Physical Volumes, Persistent Volumes (PVs).
Public cloud environments with multiple availability zones raise additional issues. If you are planning to use a public cloud with multiple zones, you will want to become familiar with the topology aware storage class configurations.
Getting Started
The Kubernetes ecosystem has made it easy to deploy self-managed databases. Tools such as Helm and Kustomize provide automated installation and initial configuration. Marketplaces like OperatorHub.io, the OpenShift Lifecycle Manager and Google Kubernetes Marketplace also provide easy getting started workflows.
If you have a default storage class setup, the below commands enables you to deploy PGO:
kubectl create namespace pgo>
kubectl apply -f https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.6.2/installers/kubectl/postgres-operator.yml
Within a few minutes, you should be up and running and ready to deploy a database to your Kubernetes environment.
Ready for a Deeper Dive?
The CNCF research is important validation of what we are seeing in the market. Users are adopting databases on Kubernetes. Operators, Helm, Kustomize and improvements in persistent storage have made this a much easier option. That said, there are of course areas where you may want to do a deeper dive include:
- Using TLS to Secure Your Database On Kubernetes
- Setting Up Monitoring for Your Database On Kubernetes
- Active Active Database Federation on Kubernetes
Deploying Postgres on Kubernetes is one of the many ways to benefit from the power and efficiency of Postgres. At Crunchy Data, we are seeing customers have success with this model and further grow their adoption of trusted open source Postgres. Now is a great time to get started running Postgres on Kubernetes.
Related Articles
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read
- PostGIS Performance: Simplification
3 min read
- How to Read Postgres EXPLAIN: A Guide to Scan Types
9 min read