Using Kubernetes Deployments for Running PostgreSQL
Crunchy Data
5 min readMore by this author
Running PostgreSQL databases in containerized environments is more popular than ever and is moving beyond running only in local, development environments and into large scale production environments. To answer the need to orchestrate complex, database workloads, the Crunchy Data team created the PostgreSQL Operator to automate many typical database administrator tasks at scale:
- Provisioning new PostgreSQL clusters
- Scaling up replicas
- Setup and manage disaster recovery, high-availability, and monitoring
- Allocate resources (memory, CPU, etc.) and suggest nodes for databases to run on
- Mass applying user policies
- Performing major/minor upgrades
and more. In order to keep all of its PostgreSQL databases up and running, the PostgreSQL Operator uses Kubernetes Deployments, which provides an API to manage replicated applications. In order to understand why this is, first we need to understand about running stateful applications with Kubernetes.
Running Stateful Applications With Kubernetes
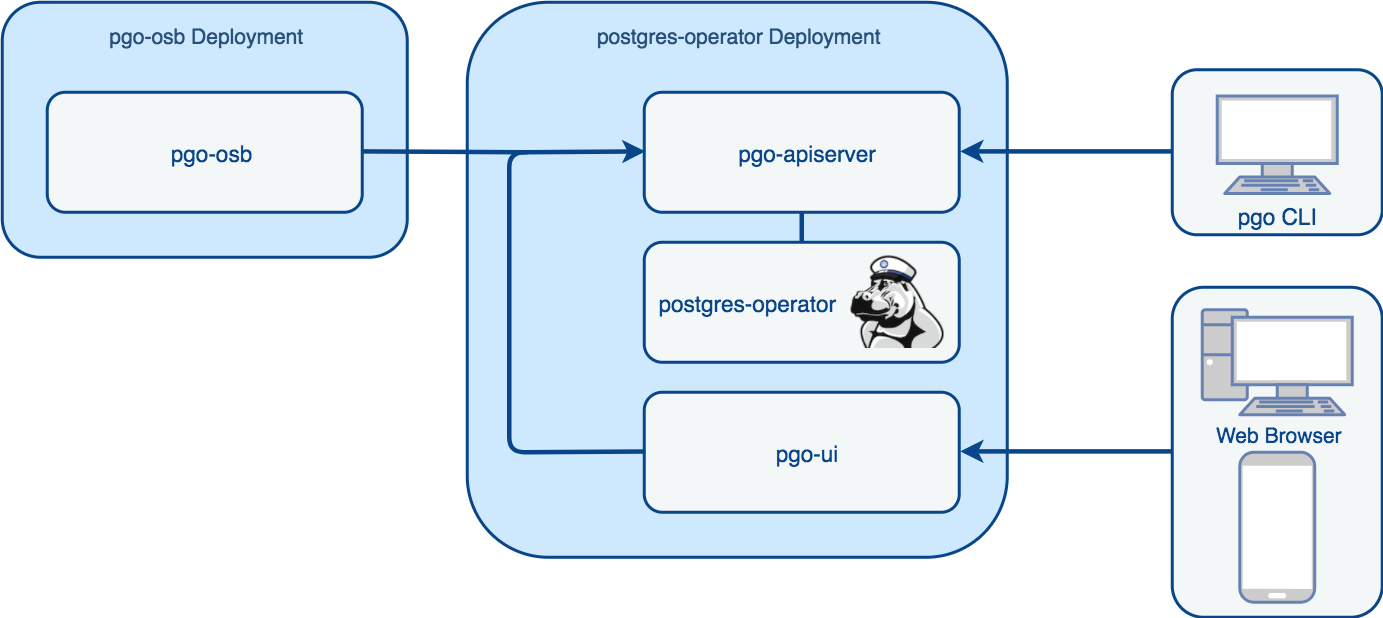
Kubernetes began as a project that focused on managing the compute workload of container-based applications and did not worry about storage management. As the project has matured, the Kubernetes community has incorporated the building blocks that make it possible to run stateful workloads, such as databases, in a Kubernetes environment. Tools such as the Operator Framework have allowed developers to capture the various nuances of managing complex stateful workloads, e.g. a relational database, and take full advantages of Kubernetes ability to schedule and manage container runtimes.
When it comes to managing stateful applications, Kubernetes offers a few different solutions. We are going to focus using Deployments. A Deployment manages pods based on a particularly container image and operates in a replicated Kubernetes environment, i.e. it uses a ReplicaSet and aim to have a given number of pods running at any time.
Why Run PostgreSQL With Kubernetes Deployments?
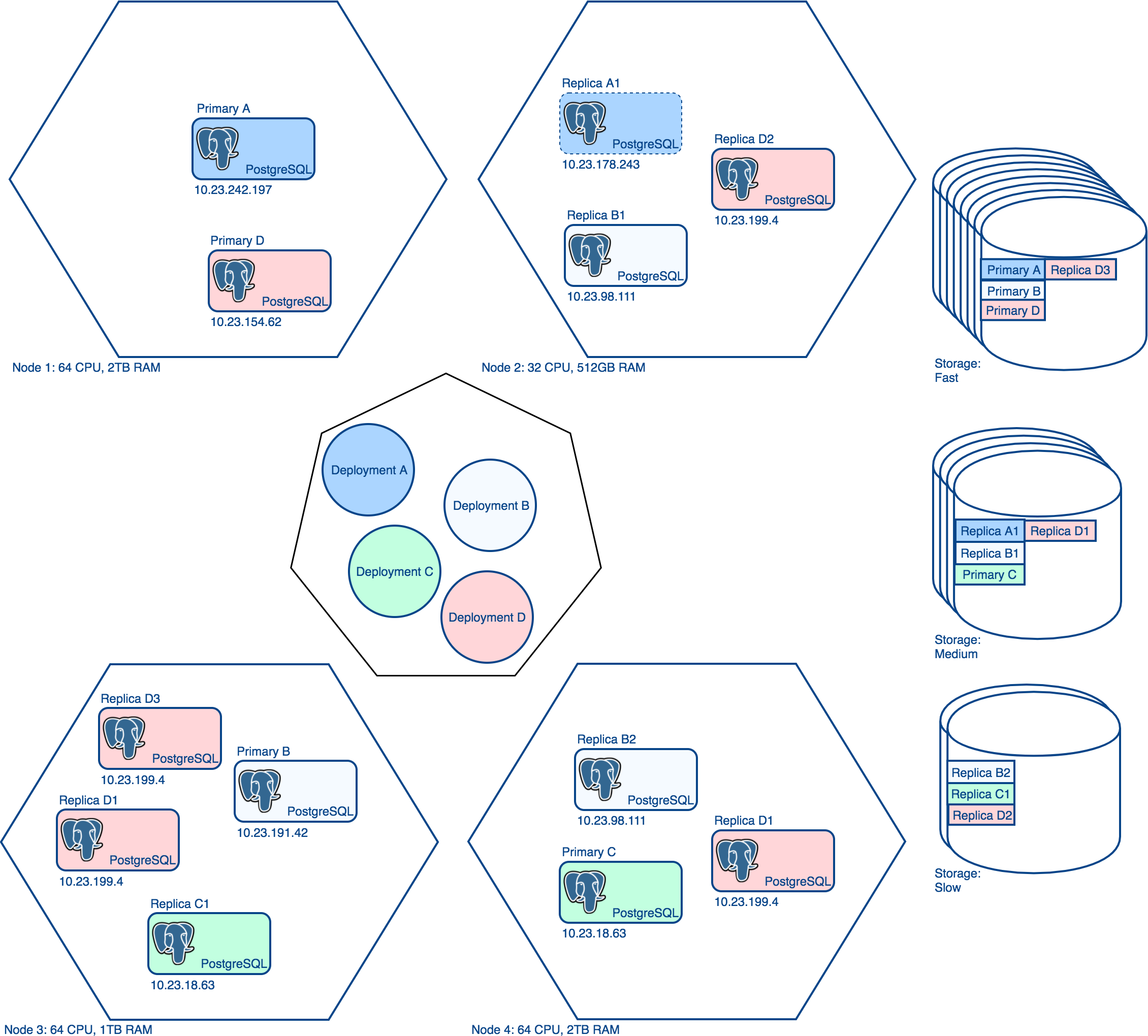
Running your clusters with Kubernetes Deployments gives you flexibility in how you operate your cluster and other advantages, including:
Using Different Storage Classes
Often in database environments, you will have databases running on different types of disks. For example, you may want your primary databases to run on fast disks, replica databases to run on medium-speed disks, and development databases to run on slow disks.
The PostgreSQL Operator accounts for this by allowing you to create different storage classes for persistent volumes (PVs). When you provision a new database using the PostgreSQL Operator, whether its a primary or a replica, you can specify which storage class for the new persistent volume to use.
Additionally, utilizing Kubernetes Deployments allows you to use different storage engines within the same deployment. For instance, you may want to run your primary instances on NFS preallocated persistent volumes but use dynamic storage classes with your replicas using an engine like Gluster.
Choosing Your Operating Environment
In Kubernetes, a node is a machine (physical or virtual) that is responsible for executing workloads. For our purposes, a node is where the PostgreSQL database software runs.
Often a production requirement of running PostgreSQL (let alone any database) is to select the hardware for your database system to operate in. For instance, you typically do not want you primary and replica instances to run on the same physical machine as any problems to the machine could impact your database system availability. Similarly, you may want to have your primary instances run on nodes that have better hardware than your replicas.
The PostgreSQL Operator uses node labels in Kubernetes to create “node affinity” rules, such as “do not deploy a primary and replica to the same node.” Users can specify specific node label rules on each part of a PostgreSQL Deployment (primary and replicas) that influence which node a database workload is scheduled on. This enables a fine-tuned placement of a PostgreSQL database cluster across a Kubernetes nodes.
Additionally, the PostgreSQL Operator also allows you to specify what CPU and memory resources to each primary or replica instance deployed, giving you finer grained control over how many resources a database can use.
Selective PostgreSQL Version Upgrades
A favorite past time of every PostgreSQL administrator is planning upgrades and ensuring that they can minimize downtime for all affected users. There are many different strategies for upgrading, including some special ones for very large clusters, all of which involve different levels of outages. A common theme for upgrading multiple clusters involves using “rolling upgrades,” or selectively upgrading each cluster. In addition to often being easier to manage, this gives the database administrator the ability to rollback an individual cluster should the upgrade fail.
The PostgreSQL Operator comes with the ability to perform selective upgrades across all of the PostgreSQL clusters its managing using a combination of Kubernetes selectors and individual PostgreSQL images.
Conclusion
There are other ways to run PostgreSQL clusters in a Kubernetes environment (in fact we provide some examples in the Crunchy Container Suite). The architecture decision to use Deployments in the Crunchy PostgreSQL Operator is specifically geared around flexibility: high-availability: you can choose different nodes, resources, and storage solutions for your databases based upon your operating requirements.
The Crunchy PostgreSQL Operator is actively being developed - we recently released version 3.1 - to help you take full advantage of running your PostgreSQL workloads on Kubernetes and ensure you can run your PostgreSQL clusters with all your good database administrator habits.
Related Articles
- Hybrid Search Patterns with Postgres and pgvector
13 min read
- Postgres 19 Compression: from pglz to LZ4
8 min read
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read