A Deep Dive into PostGIS Nearest Neighbor Search
Martin Davis
12 min readMore by this author
A classic spatial query is to find the nearest neighbours of a spatial feature. Our previous post "Won’t You Be My Neighbor? Quickly Finding Who is Nearby" discussed this capability from a PostgreSQL perspective. The PostGIS spatial data extension to Postgres can also execute nearest neighbour queries with remarkable efficiency.
In this post, we’re going to take a deeper dive into the Postgres and PostGIS internals to find out how this actually works. By the time we surface you will have a better understanding of the advanced technical capabilities and unparalleled extensibility of Postgres. You’ll also appreciate how the open philosophy of Postgres has fostered a development community whose collaboration over many years has provided powerful features that benefit numerous users.
Prepare to Dive
As a recap, the problem is to find the nearest feature, or the K-nearest features, to a given target feature out a set of spatial features. The obvious way to do this is to compute the distance from each candidate feature to the target feature, and choose the K-smallest distances. It should also be obvious that this will be extremely slow if the number of candidates is large (it is common to run queries against datasets containing millions of features).
In PostGIS spatial features are stored as records in a table, with the feature location stored as a column of type geometry or geography. The ST_Distance function computes the distance between geometries. So using the naive approach above a query could be written as:
SELECT name, ST_Distance(ST_MakePoint(-118.291995, 36.578581 ), geom) AS dist
FROM geonames
ORDER BY dist LIMIT 10;
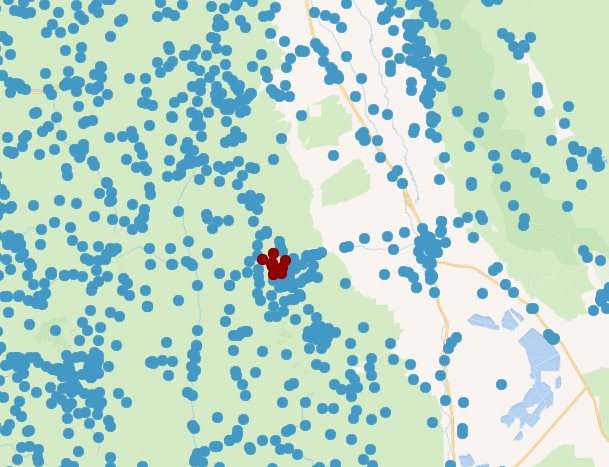
This query is being executed against a table of geographic name locations containing over two million features. It is searching for the 10 names nearest a point close to the summit of Mt. Whitney, California. As expected, it is not particularly fast, completing in around 14 seconds. The following table and map show the query results (with distance in metres):
name | dist
----------------------+--------------------
Mount Whitney | 11.247614731387534
Sierra Nevada | 127.29084391848636
Keeler Needle | 467.97664454275554
Crooks Peak | 482.3234106159308
Mount Russell | 1267.654254211147
Pinnacle Ridge | 1414.1558235265738
Arctic Lake | 1475.471505754701
Mount Muir | 1549.5739171031566
Upper Boy Scout Lake | 1684.333541189354
Wotans Throne | 1760.0677063194435
(10 rows)
The query plan confirms the reason for the slow performance: the query engine is doing a table scan and a sort in order to find the nearest features.
Limit (cost=56032553.10..56032553.12 rows=10 width=28) (actual time=14252.326..14252.330 rows=10 loops=1)
> -> Sort (cost=56032553.10..56038147.05 rows=2237580 width=28) (actual time=14252.324..14252.325 rows=10 loops=1)
Sort Key: (st_distance('0101000020E61000001DE6CB0BB0925DC0228B34F10E4A4240'::geography, geom, true))
Sort Method: top-N heapsort Memory: 26kB
-> Seq Scan on geonames (cost=0.00..55984199.80 rows=2237580 width=28) (actual time=3.719..13135.246 rows=2237580 loops=1)
Planning Time: 0.243 ms
Execution Time: 14252.413 ms
With a spatial index present PostGIS nearest neighbour support allows the query to be written as:
SELECT name, geom <-> ST_MakePoint( -118.291995, 36.578581 ) AS dist
FROM geonames
ORDER BY dist LIMIT 10;
This provides the same result but with much better performance. It executes in 7.8 ms - almost 1800 times faster! The query plan confirms that the GIST index geonames_gix is being used:
Limit (cost=0.41..3.85 rows=10 width=28) (actual time=5.896..7.533 rows=10 loops=1)
-> Index Scan using geonames_gix on geonames (cost=0.41..769145.06 rows=2237580 width=28) (actual time=5.893..7.523 rows=10 loops=1)
Order By: (geom <-> '0101000020E61000001DE6CB0BB0925DC0228B34F10E4A4240'::geography)
Planning Time: 0.184 ms
Execution Time: 7.768 ms
This is a dramatic improvement for such a seemingly minor change to the SQL. But it raises some questions:
- What is the “<->” syntax? (it certainly doesn’t look like standard SQL!)
- Clearly “<->” computes the distance between two geometries, but how does this use an index to make nearest neighbour search faster?
- How can an expression with “<->” be used in the ORDER BY clause?
- How is an extension like PostGIS able to use the nearest neighbour search provided by Postgres?
In the following sections we will plumb the depths to answer these questions and demystify the mechanism of nearest neighbour search.
Down We Go
To start with, the ‘<->’ syntax is an operator. Operators can be thought of as “shorthand functions” for computing new values from an expression with one or two arguments. We’re familiar with many different kinds of operators, mostly from arithmetic. Postgres (and all other SQL databases) provides those operators to make it easy and familiar to write computation expressions.
Some operators do more than just compute values - they are recognized by the query planner and trigger the use of the indexing system. An obvious example is comparison operators such as “=”, “>”, and “<”. The query planner recognizes when these operators are used in a WHERE clause, and can construct a query plan that uses an index to improve performance, if an appropriate one (typically a B-tree) is present. Note these operators all return a boolean result. Postgres calls these search operators, because they determine how an index is searched to decide whether or not a given row (or combination of rows in the case of a join) is included in the query result set.
Into The Depths
Up to this point every SQL database works in a similar way. But Postgres was designed from the start to be extensible in almost every aspect.
The most common extension is to define new data types to represent different kinds of data. Since a key task of a relational database is to use indexes to query data efficiently, Postgres provides a wide variety of index methods for data access. These include the well-known B-tree index, as well as special-purpose ones such as GIST, GIN and several others.
The query planner needs to know when and how indexes can be used in queries against new data types. This is done by allowing new operators to be defined for a given combination of data type and index method.
Operators are bound to a function that computes the value for the operator expression. They also supply metadata which helps the query planner apply the index in more situations. The set of operators for a data type and index method is called an operator class (usually abbreviated to opclass.) Note that this means that an operator symbol (such as “=”) may be overloaded, that is, map to operators in many different opclasses; the planner uses the data type of the arguments to determine which one to invoke.
Opclasses also define support routines. These routines are the interface between the index method and the data type. They are called by the index implementation to return information about data type values. A single support routine may be called during evaluation of several different operators, so each operator is assigned a strategy number, which is passed to the support routine to indicate which operator is being used. Performance is key here, so these routines are written in C, the language of the Postgres core.
At this point we have shown how the Postgres extension framework supports defining new data types and operators, and binding them to index methods. Prior to 2010, only search operators were available, allowing only standard boolean filtering. A clever team of developers saw a way to enhance the framework to support nearest neighbour search. They proposed modifying the GIST index method to allow this. GIST (Generalized Index Search Tree) is itself an extensible index method framework. It supports creating many different kinds of indexes for data which require more than the one-dimensional B-tree index. So this one change could benefit many different data types.
The modification consisted of adding a search strategy that uses best-first-search to query the index, along with a new support routine called distance. The nodes in the index tree are searched in order of their potential distance from the search value. The active search nodes are kept in a priority queue ordered by distance, so that near nodes and values are found first. This is well-described in a 1995 paper entitled Nearest Neighbour Queries by Roussopoulos et al. This strategy provides excellent performance, because nearby values are found quickly, and far-away values are usually never retrieved.
In order to allow queries to make use of this new search strategy the concept of ordering operators was created. Ordering operators such as “<->” compute distance between data type values. When an ordering operator appears in an ORDER BY clause, the planner knows to invoke nearest neighbour search using the data type the operator is defined for. Like all index-based queries, nearest neighbour search reads a stream of values out of the index. Thanks to the best-first search, the values are provided in order of increasing distance. So when a LIMIT clause is provided (which is usually the case), only the required number of values are actually retrieved.
The nearest neighbour enhancement was released in 2011 in Postgres 9.1.0. Since it was based on GIST the initial release was able to provide nearest neighbour support for several different data types, including the built-in point type and the pg_trgm type for text matching using trigrams.
Ascend with PostGIS
With all this said, we can show how the PostGIS extension makes use of this framework. PostGIS defines data types to represent spatial data. In the following we discuss the geometry data type; the geography type works in a similar way. The geometry data type uses a spatial index called an R-tree (“range tree”). R-trees allow indexing data values which are defined in 2 (or more) dimensions. The PostGIS R-tree index is defined using the GIST framework, and so is able to take advantage of the nearest neighbour search capability supported by GIST.
The first definition is the <-> operator. It is bound to the function geometry_distance_centroid to compute the distance value between geometries:
CREATE OPERATOR <-> (
LEFTARG = geometry, RIGHTARG = geometry,
PROCEDURE = geometry_distance_centroid,
COMMUTATOR = '<->'
);
(The name geometry_distance_centroid is legacy - the function actually computes the exact distance between geometry values.) The operator definition provides metadata to assist the planner in constructing plans - in this case, the fact that the distance function is commutative (so that the arguments can be reversed without changing the answer).
To allow the geometry data type to use the GIST index method PostGIS defines an opclass called gist_geometry_ops_2d. The opclass contains a variety of operators. The most commonly used is the && operator, a search operator that allows locating spatial objects using the R-tree index. All this is specified in the DDL for the opclass definition, which starts like this:
CREATE OPERATOR CLASS gist_geometry_ops_2d
DEFAULT FOR TYPE geometry USING GIST AS
STORAGE box2df,
OPERATOR 1 <<,
OPERATOR 2 &<,
OPERATOR 3 &&,
...
The <-> distance ordering operator is defined in the opclass like this:
OPERATOR 13 <-> FOR ORDER BY pg_catalog.float_ops
The required GIST support routines are also defined in the opclass, including the one for nearest neighbour:
FUNCTION 8 geometry_gist_distance_2d (internal, geometry, int4)
8 is the id of the GIST distance support routine, and geometry_gist_distance_2d is a PostGIS C function which computes the distance between geometries. The float_ops data type specified for the operator indicates the ordering semantics of the values returned by the distance function.
And that’s all that is required. The Postgres query planner can now recognize that when <-> is used on PostGIS geometry values in the ORDER BY clause, the query plan can use the nearest neighbour search strategy using the GIST R-tree index.
There is one further aspect of nearest neighbour search. The search is performed using a single target data value. This means that NN search is not in itself a way of joining tables. So how can you specify a query that finds the nearest neighbours of many features in a table out of another table? This is where the recent support for LATERAL subqueries comes to the rescue. It essentially acts as a loop, allowing many features to be queried for their nearest neighbours. A typical query using LATERAL looks like:
SELECT loc.*, t.name, t.geom
FROM locations loc
JOIN LATERAL (SELECT name, geom FROM geonames gn
ORDER BY loc.geom <-> gn.geom LIMIT 10) AS t ON true;
Back at the Surface
That completes our excursion into the depths of nearest neighbour search in PostGIS. Here’s the dive notes from the descent:
- Postgres extensions inform the query planner how to use indexes by defining an opclass with operators and support routines, bound to a data type and an index method
- Starting in Postgres 9.1 a framework was added to give index methods the capability of performing nearest neighbour queries
- The GIST index method uses a best-first search strategy to execute nearest neighbour search efficiently
- PostGIS uses this framework and the R-tree spatial index to provide excellent performance for nearest neighbour queries on its spatial data types
It’s interesting to compare Postgres to the implementation of nearest neighbour in other relational databases. One database uses a special function SDO*NN in the WHERE clause to trigger nearest-neighbour search. Another uses a special function STDistance in both the WHERE clause and the ORDER BY clause. Since the code is not open one can only speculate, but presumably the query planners have been specially modified to recognize these functions.
That’s a big difference to Postgres, where nearest-neighbour search is a general-purpose mechanism, implemented using the standard extension framework. Thus many other kinds of data can utilize the same approach, including data types and index methods which have not yet been envisioned.
You now have a deeper understanding of how PostGIS performs nearest neighbour query in a highly performant way, using the R-tree spatial index and the best-first query strategy. You have also seen how this is provided using several different kinds of extension points provided by the Postgres platform. I also encourage you to try writing your own PostGIS nearest neighbour queries which you can do from this PostGIS container that is easy to set up.
The wider story is that these powerful and unique capabilities are being developed in an open, collaborative way by numerous developers around the world. This is why Postgres truly deserves its position as the leading open source relational database.
Related Articles
- British Columbia, Time Zones, and Postgres
6 min read
- Postgres Serials Should be BIGINT (and How to Migrate)
11 min read
- Postgres 18 New Default for Data Checksums and How to Deal with Upgrades
4 min read
- PostGIS Performance: Simplification
3 min read
- How to Read Postgres EXPLAIN: A Guide to Scan Types
9 min read